
Il y a environ 1 an, nous avons pour la première fois organisé un « Ship It ». C’est une période pendant laquelle, en équipe, nous construisons un livrable qui est montré à l’entreprise au bout de 24h. Cette année, le format a eu tout autant de succès.
Configuration KOCT
Une première équipe a travaillé à améliorer le processus de configuration du plugin KOCT : les sites pouvaient être entrés librement et lors de la resynchronisation, les prêts n’étaient pas enregistrés si le code du site saisi dans KOCT n’était pas le même que celui saisi dans Koha.
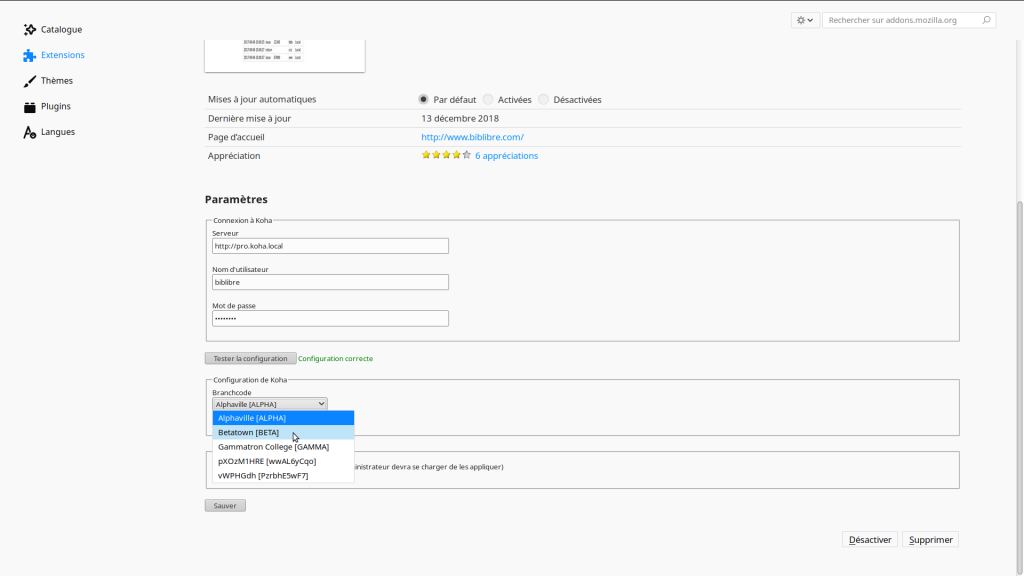
L’objectif était donc de développer un plugin Koha utilisé dans KOCT pour limiter ce problème. Ce plugin permet de lister les bibliothèques au lieu de faire une saisie manuelle:
Le Shiptit précédent, un patch a été soumis à la communauté pour ajouter la route: Bz 16497. Le process communautaire et le temps investi a été plus lourd que la valeur ajoutée. D’où ce choix cette année.
Il est possible dans Koha de développer des fonctionnalités en dehors de « son cœur » grâce aux plugins. Celui ci est un exemple simple qui montre comment écrire une route dans l’API REST. La route rend tout simplement la liste des sites disponibles dans Koha.
Elle est appelée lors de la configuration du module Firefox. Avant, si le branchcode était erroné, les prêts étaient tout de même enregistrés hors ligne. Maintenant, la saisie erronée n’est plus possible.
=> https://git.biblibre.com/biblibre/koha-plugin-libraries-api
Auto-documentation des installations
Une autre équipe a travaillé à améliorer les outils internes de déploiement d’un point de vue de la documentation.
Nous sommes capables de déployer des instances standardisées, il était nécessaire de solidifier la génération de la documentation de ces installations. Ce Shipit a permis d’améliorer l’outil de déploiement de Koha et de fluidifier nos process internes.
Note : le résultat n’est pas publiable car il se base sur de nombreuses contraintes qui sont celles de nos processus internes.
Étudier/retravailler les données lors des migrations
Le besoin que la troisième équipe a souhaité adresser était de partager les pratiques d’utilisations et les besoins des chefs de projets dans l’étude des données pendant un projet. Nous avons partagé plusieurs pratiques d’outils d’analyse de données bibliographiques, lecteurs, prêt etc.
- Catmandu: Outil en ligne de commande permettant d’analyser, filtrer, transformer des données d’un format dans un autre
- Grep / cut / sed / less / cat / file etc. : permet d’obtenir des analyses de manière très souple, rapide, précise
- Dataiku: Outil non libre permettant graphiquement de visualiser, analyser et traiter des données
- Open Refine: Outil libre permettant également d’analyser et traiter des données
- Script spécifique: Nous avons évoqué la possibilité de développer un script, c’est la solution la plus souple
- Outils éliminés : Libre Office Calc, Google spreadsheet
- Outils non mis en avant dans cet atelier: Data Wrangler Geany Xslt MarcEdit Talend, XmlStarlet

Il n’y a pas de « gagnant » à notre étude. Nous avons partagés nos pratiques et astuces. Chaque outil a ses avantages et inconvénients, ses usages et ses utilisateurs. Le tout est récapitulé sur le document suivant : https://docs.google.com/spreadsheets/d/1XXfaL8VtdkwWQss4emHc1hllRJM46mQb2DWBgHURBHY/edit#gid=171428662
Pourquoi je ne peux pas réserver un document ?
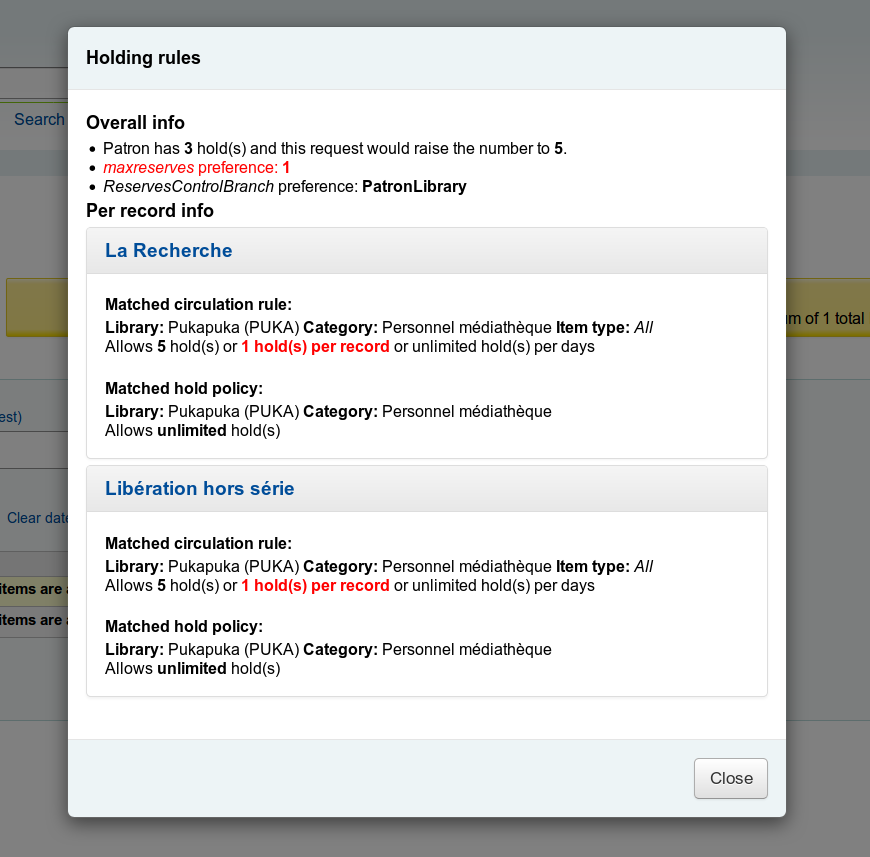
Une équipe a proposé une évolution de Koha pour identifier rapidement ce qui fait qu’une réservation est faisable ou pas.
En effet, les règles métier peuvent être suffisamment complexes pour passer un petit moment à comprendre le pourquoi. Cet outil résume en quelques lignes les paramétrages et règles prises en compte dans sa décision. L’écran s’affiche à partir d’un bouton spécifique sur l’écran de réservation et peut être utile au bibliothécaire ou au support :
Conclusion
C’est un format que j’aime bien parce qu’il contraint à rester concentré sur un sujet en équipe. Le temps demandé est suffisamment court pour que le focus soit respecté et assez long pour permettre une livraison concrète.
